Local環境の整備
dbtではLocalで実行するdbt-coreとクラウド上で実行するdbt-cloudの2種類がある。 今回は軽くテストするためLocalで実行するdbt-coreで進めてみる
</aside>
Python環境の整備
- PC上でpython, pipを用意する
- dbt用のフォルダーを作成
- VScodeのターミナルを開き、作成したdbt用のフォルダーまで移動
- 例: cd dbt-core-demo
- 出力:PS D:\python\dbt-core-demo>
- 以下のコードでdbt用のバーチャル環境を作成
python -m venv dbt-core-demo
- バーチャル環境を起動
.\\Scripts\\activate

- dbtとdbt-bigqueryをインストール
pip install dbt-core dbt-bigquery

- dbtはインストールされているかどうかを確認
dbt --version
- 以下のコードでdbt parchaseを構築
dbt init dbt_core_demo
- 構築完了後、connectionを設定する流れになるが、こちらはctrl+Cで飛ばす。
- 補足すると、ここで必要な情報を入力することもできるが、コードでconnection情報を一括で管理できるため、コードで管理したほうが楽

- local PCのC:\Users\S15378\.dbtに入って、profiles.ymlを作成
- 以下の感じでconnection情報を入れる
dbt_core_demo: target: test outputs: test: dataset: dbt_test job_execution_timeout_seconds: 300 job_retries: 1 keyfile: D:\\python\\dbt-core-demo\\dbt-core-demo\\dbt_core_demo\\service-account-key.json location: US method: service-account priority: interactive project: honbu-datamarketing-training threads: 1 type: bigquery dev: dataset: dbt_demo job_execution_timeout_seconds: 300 job_retries: 1 keyfile: D:\\python\\dbt-core-demo\\dbt-core-demo\\dbt_core_demo\\service-account-key.json location: US method: service-account priority: interactive project: honbu-datamarketing-training threads: 1 type: bigquery
- 以下の感じでconnection情報を入れる
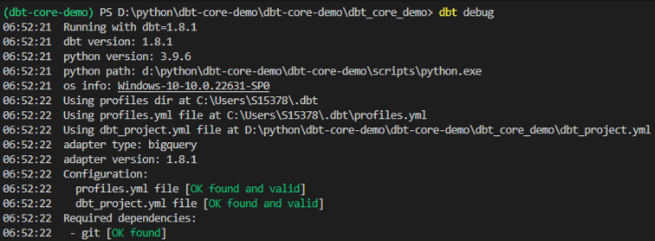
- vs codeのターミナルに戻って、dbt initで作成したparchaseまで移動して、dbt debugを実施して、connectionできるかどうかを確認
dbt-bigquery用のモデル説明
dbtの便利なところは、{{}}の方法で変数の引用ができるため、SQLでも簡単にPythonのような関数引用ができる
default パターン
- 以下のように、変数を引用せず、そのままBigquery用のsqlをファイルにコピー
with customers as (
select
id as customer_id,
first_name,
last_name
from `dbt-tutorial`.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from `dbt-tutorial`.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
)
select * from customer_ordersTableを指定するパターン
- 以下のように、出力を「Table」に指定する場合、SQLの実行結果がBigqueryにtableとして出力される
{{ config(materialized='table') }}
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data変数を引用する場合
- 例えば、table bを作成するため、先にtable aを生成して、from table aの形でtable bを作成する場合、以下の方法でtableをお互いに引用することができる
--table aを作成
{{ config(materialized='table') }}
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
--table aを引用して、table bを作成
--変数はtable aのファイル名そのまま
select *
from {{ ref('my_first_dbt_model') }}
where id = 1
table, viewの生成をコントロールする方法
- table, viewどちらを生成するかは、二つの方法でコントロールできる
- sqlファイル内で指定。sqlの前に{{ config(materialized=’table’) }}を追加
{{ config(materialized='table') }} with source_data as ( select 1 as id union all select null as id ) select * from source_data - dbt_project.ymlの設定でコントロール
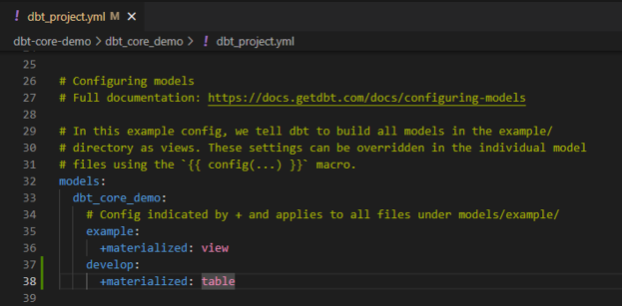
- 以下のように、folder:+materialized: view あるいかtableで、フォルダー全体を指定できる
- sql内とdbt_project.ymlファイル内両方指定する場合、sql内の方が優先される
- 以下のように、folder:+materialized: view あるいかtableで、フォルダー全体を指定できる
- sqlファイル内で指定。sqlの前に{{ config(materialized=’table’) }}を追加
modelsのベストプラクティス
withを大量に使う場合、サブクエリを別のmodelに分散し、with内で分散されたmodelを引用するのは推奨されている
- 推奨されないパターン
with customers as (
select
id as customer_id,
first_name,
last_name
from `dbt-tutorial`.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from `dbt-tutorial`.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
)
select * from customer_orders- 推奨されるパターン
with customers as (
select *
from {{ref('ds_customers')}}
),
orders as (
select *
from {{ref('ds_orders')}}
),
customer_orders as (
select *
from {{ref('ds_customer_orders')}}
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
dbt test機能の使い方
Generic Tests
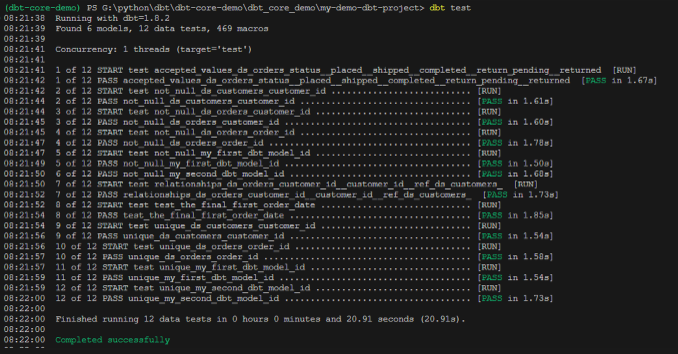
queryを実行する前に、特定のテーブルの特定の列は特定の条件を満たしているのかを確認できる機能です。
- models/フォルダーの中に、schema.ymlが入っていますが、こちらのyamlファイルで上記の条件を設定することができます。
version: 2
models:
- name: ds_customers
description: This table has basic information about a customer, as well as some derived facts based on a customer's orders
columns:
- name: customer_id
description: This is a unique identifier for a customer
tests:
- unique
- not_null
- name: first_name
description: Customer's first name. PII.
- name: last_name
description: Customer's last name. PII.
- name: ds_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique
- not_null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships:
to: ref('ds_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: 'the status of the order data'
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: my_first_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
data_tests:
- unique
- not_null
- name: my_second_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
data_tests:
- unique
- not_null- 以下の条件でテストを実施することができます
- unique
- プライマリキー列検証用。重複があればエラー
- not_null
- nullが入っているであればエラー
- relationships
- JOINをする時、マスターテーブルと不一致があるかどうかを確認する
-
- relationships: to: ref('ds_customers') field: customer_id
- accepted_values
- status等よく使う。Listに含まれていない値が入っているならエラー
-
- accepted_values: values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- unique
- dbt testで定義したGeneric Testsを実行できます
Singular tests
SQLで指定できる、より柔軟性があるテスト方法です。 ただ、ファイルごとにSQLを作成する必要があるので、generic testsより時間かかる
- singular test用のSQLをtestsフォルダーに入れる
select
first_order_date
from {{ref('finals')}}
where first_order_date > '2019-01-01'- dbt testで、shcema.ymlで定義した条件と、sqlで定義した条件を両方実施される

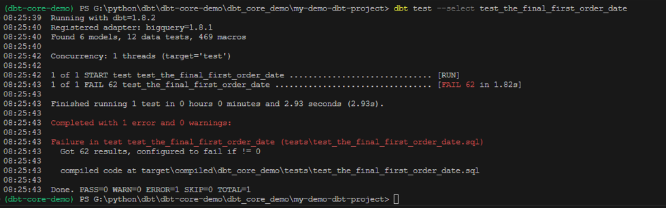
- dbt test —select test_the_final_first_order_dateの感じで、dbt test —{file name}で、singular testを一つ選んで実施できる
ドキュメンテーション
SImple Documentation
- 以下の順番で簡単にデータ定義ドキュメントを生成できる
dbt docs generate
dbt docs serve
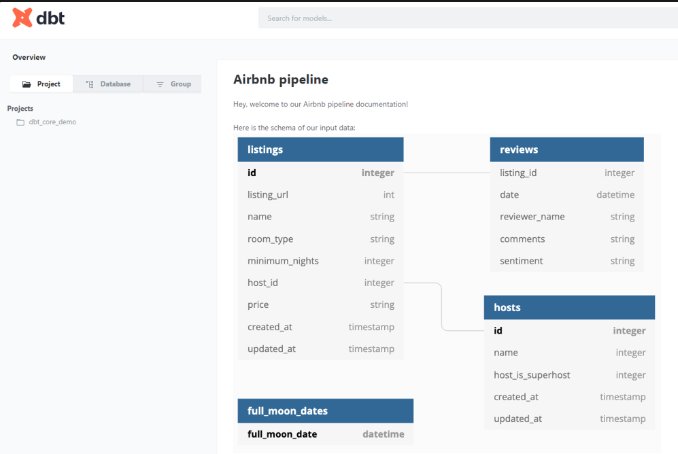
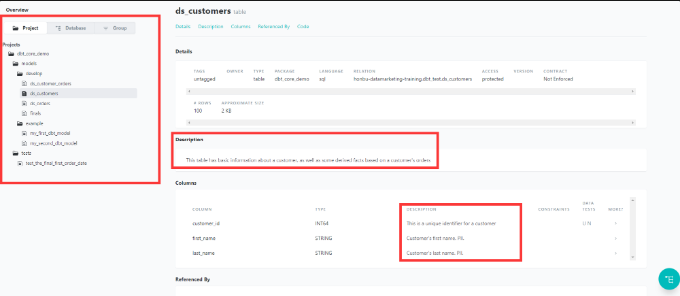
- データベースの構造、各テーブルのdiscriptionと制限は生成されます
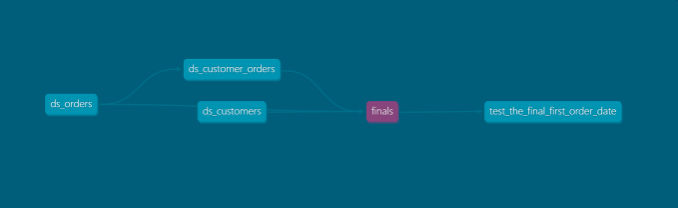
- テーブル間のリレーションが生成されます
Markdown Documentation
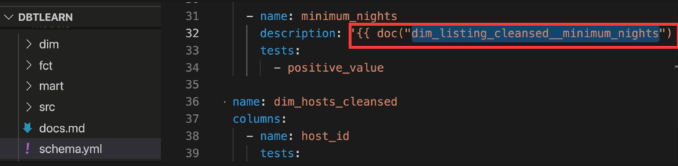
documentationはそのままmarkdownファイルを引用することができます。 models/フォルダー内に出、引用したいmarkdownファイルを作成して、 description内で引用するか、overviewでそれを引用するかができます。
- description内で引用するパターン
- overviewを引用するパターン
{% docs __overview__ %}
# Airbnb pipeline
Hey, welcome to our Airbnb pipeline documentation!
Here is the schema of our input data:

{% enddocs %}