
やりたいこと
アドビのローデータをクライアントからもらったので、データの中身の確認と簡単な集計をやりたいです。
アドビのローデータの構造
adobe analyticsのデータフォードから、アドビのローデータを出力することができます。出力されたデータの一覧は以下になります。
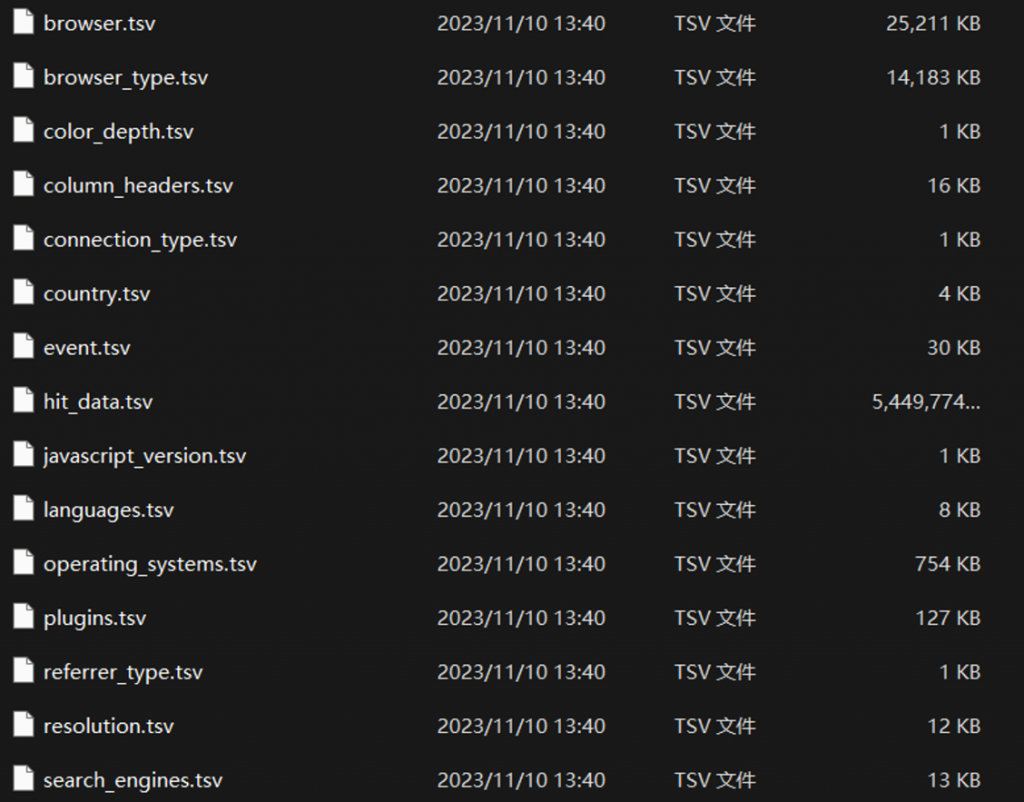
そのままexcelで読み上げることもできますが、今回は少し特殊なケースで、メインデータのhit_data.tsvは5ギガになって、Excelでも、VScodeでもそのまま読み上げることが難しいです(PCの悲鳴が聞こえるまで)。そのために、bigqueryにデータを入れて集計をしようと思ってます。
流れ
用意すべきこと
1.すべてのデータをGCSにアップロードしておく
2.スキーマファイルを用意する
bqコマンドでTSVをGCSからBQにアップロードすることができますが、事前にスキーマファイルを用意しないといけないです。スキーマファイルのサンプルは以下です

つまり、各列の定義が入った辞典をlistに追加することです。
hit_data.tsvの列名は、column_headersに入っていますが、typeが入ってないです。
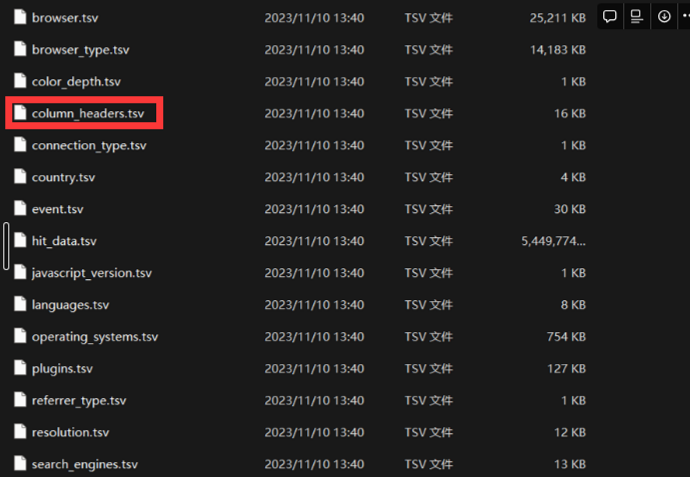
そのため、columns_headersをベースで、スキーマの定義をまず生成する必要があります。
サンプルコートは以下です。Vertex aiのワークベンチでコードを実行しました
import pandas as pd
import json
def save_list_as_json(data_list, filename):
with open(filename, 'w') as f:
json.dump(data_list, f)
def load_list_from_json(filename):
with open(filename, 'r') as f:
data_list = json.load(f)
return data_list
df = pd.read_csv(r'column_headers.tsv', sep='\t',encoding='latin1')
json_list = []
for i in df.columns:
json_list.append(
{
"name": i.replace('-','_').replace('.','_').replace(' ','').replace('(','').replace(')',''),
"type": "STRING",
"mode": "NULLABLE"
}
)
save_list_as_json(json_list,'header_json.json')上記のコードを全部実行した結果、ワークベンチにスキーマの定義が入ったJSONファイルが保存されます。
JSONファイルをGCSに保存しておきます
!gsutil cp header_json.json gs://{gcs bucket}/adobe_data/header_json.jsonこれで準備が完了ですWhen
adobe analyticsのデータをBigqueryにロード
bigqueryにアクセスして、cloud shell editorを開く
以下のコードで、GCSに保存したファイルをcloud shell editorの仮想環境にコピーする
gsutil cp gs://{gcs bucket}/adobe_data/header_json.json ./header_json.json以下のコードでアドビのデータをBigqueryにロードする
bq load --source_format=CSV --autodetect --field_delimiter='\t' \
--allow_quoted_newlines --allow_jagged_rows --max_bad_records=5 \
{gcp project}:{bigquery dataset}.{bigquery table} \
gs://{gcs bucket}/adobe_data/hit_data.tsv \
./header_json.json上記実行した後、Bigqueryでadobe analyticsのローデータを確認できます